Guides
Issues
FAQ
Overview
Classification Cohorts enable publishers to reach their non-endemic audience through data modeling. Publishers select a dataset containing categorized users—e.g. by age ranges—and Permutive uses the publisher’s audience data to learn which behavioral patterns predict a user’s membership to a distinct category, such as those in the18–35 age range.
Classification Cohorts can be built using either partner data or first-party data, allowing publishers to scale valuable data from brands and data providers or their own declared data to make informed targeting decisions across their whole audience.
Why Use Classification Cohorts?
Reach your non-endemic audience — When publishers receive briefs from advertisers requesting non-endemic audiences, they need a way to prove they have these audiences and that they can reach them at sufficient scale. Building Classification Cohorts with partner data allows publishers to reach their non-endemic audience by identifying which of their users have similar behavior to those of their partners, such as brands or data providers. For example, an auto publisher may work with Rolex to identify which of their users are luxury watch intenders. Scale your declared first-party data across your whole audience — With the availability of third-party data decreasing, more and more publishers are investing in capturing declared first-party data, such as user information collected during sign-up or the responses to surveys. Building Classification Cohorts with first-party data allows publishers to scale their high fidelity understanding of a subset of their audience to identify and reach users across their entire audience. For example, a food and drink publisher responding to a brief from a vegan food retailer may survey a small set of their users and leverage this dataset to identify users across their total audience according to diet preference.Concepts
Definitions
-
Seed Dataset: A set of users each assigned to one of a fixed set of categories, called labels. For example, diet information from a brand might consist of a set of hashed email addresses each assigned one label from
vegan,vegetarian,carnivore,other. - Label: The set of categories users in the seed dataset can belong to and that the model predicts for. A user is assigned to exactly one label since Classification Cohorts are designed for use-cases where you want to enforce mutual exclusivity.
- Classification Model: The seed dataset is trained against the publisher’s custom cohorts (excluding those using third-party data) to produce a Classification Model. For a given set of custom cohorts that a user belongs to, this model predicts the confidence with which the user belongs to each of the model’s categories (labels).
-
Confidence Threshold: When we evaluate the model for a user, we will make a prediction if the user should be assigned to label
A,B, orC. Publishers can specify a confidence threshold such that users are only assigned to a label if that minimum confidence threshold is met or exceeded. For higher thresholds, confidence in the accuracy of the classification increases but audience reach decreases. Conceptually, at 0% confidence, the model assigns a label for 100% of your users but its predictions are tantamount to choosing a label at random. At 100% confidence, the model assigns labels only for those users in the seed dataset, and therefore provides 0% increase in reach. - Classification Cohort: At each confidence threshold, publishers can create a Classification Cohort for each label in the model. A user falls into the Classification Cohort if the minimum threshold is met for that label.
Data Model

- One Classification Model can be created for one partner Seed Dataset.
- Many Classification Models can be created for one first-party Seed Dataset, parameterized by the choice of 2–4 custom cohorts for labels.
- Many Classification Cohorts can be created for one Classification Model, parameterized by the confidence threshold and the model’s labels.
Workflows
Building a Classification Model
Publishers select a seed dataset—partner data or first-party data—which is joined with the publisher’s custom cohort user data to form training data. During training, the Classification Model learns patterns in the cohorts that distinguish the different labels in the seed dataset.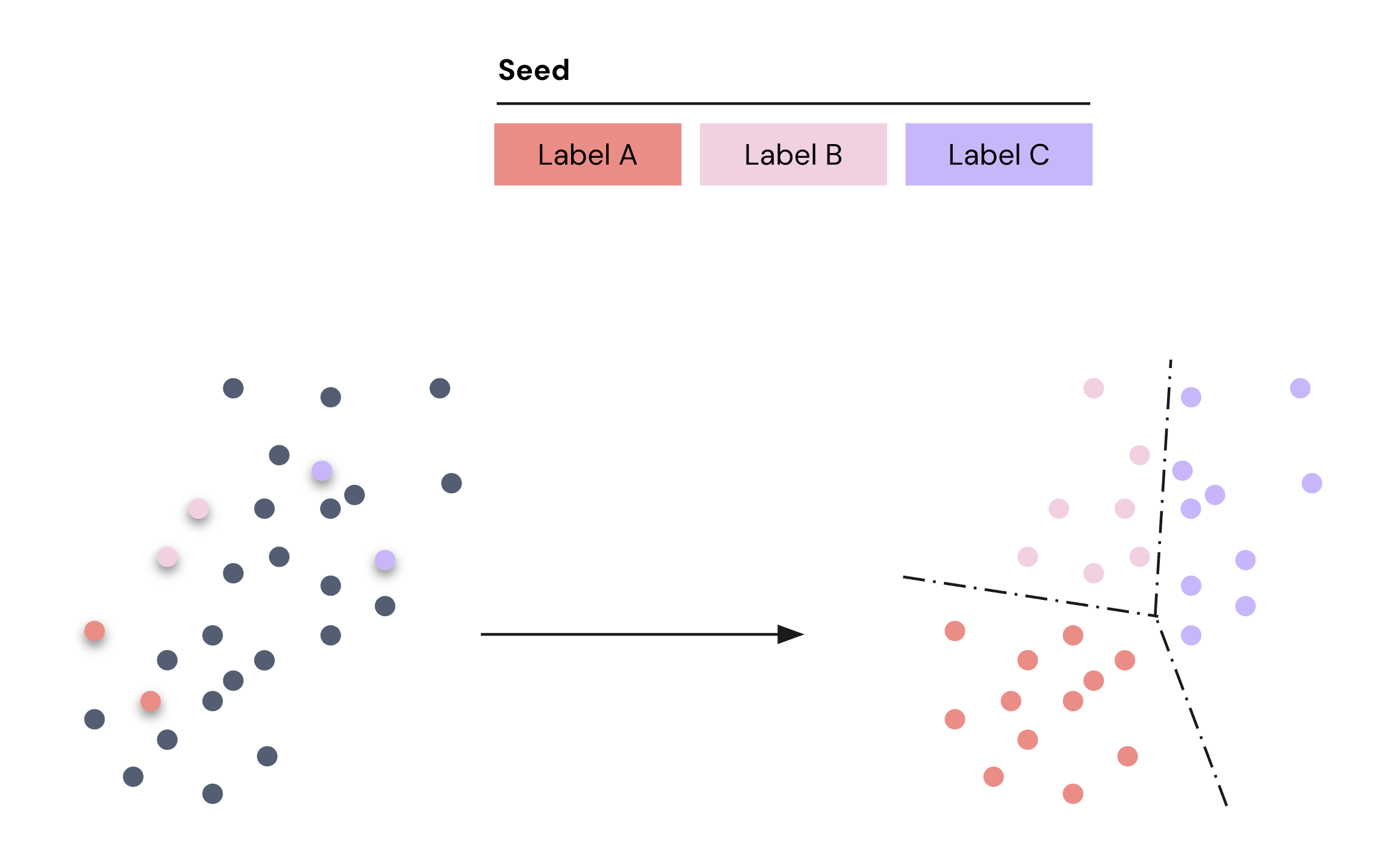
Deploying a Classification Cohort
A Classification Cohort is created from a Classification Model by first choosing a confidence threshold and then selecting the label for which the publisher would like to create a Classification Cohort.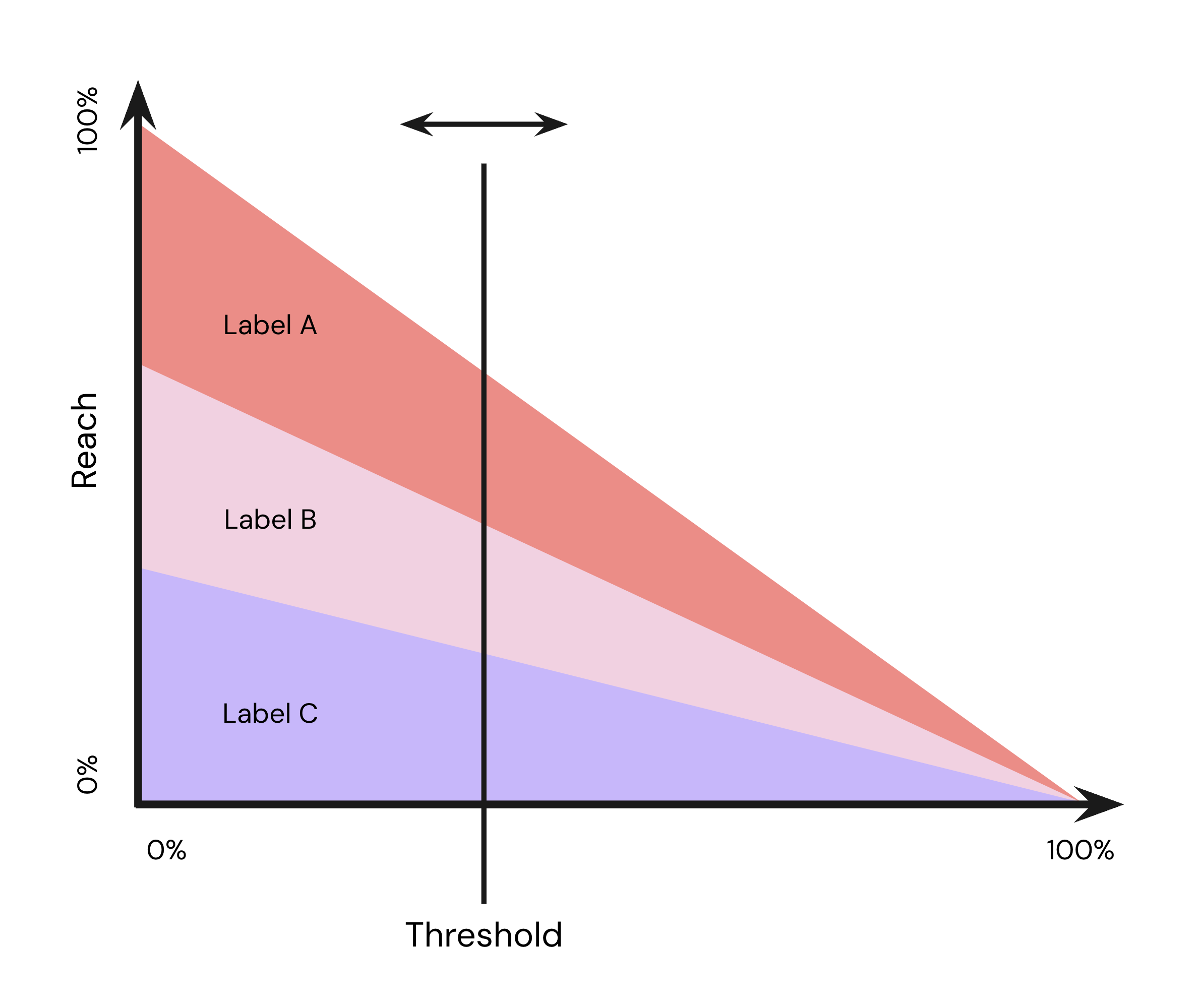
Activating a Classification Cohort
Once a Classification Cohort is deployed, the Permutive SDK manages the evaluation of users arriving on your sites and apps against the Classification Cohort to determine whether they meet the minimum threshold to fall into the label. To evaluate a user, the model uses the set of custom cohorts the user belongs to and predicts a level of confidence that the user falls into the label—if the confidence meets or exceeds the threshold for the Classification Cohort, then the user is deemed to fall into the cohort.
Guides
Step-by-step instructions for working with Classification Cohorts.Creating Classification Models
Build a model from partner or first-party data
Creating Classification Cohorts
Create cohorts from your trained model
Viewing Classification Cohorts
Manage and filter your models and cohorts
Troubleshooting
Classification Model is stuck 'In Progress'
Classification Model is stuck 'In Progress'
If your Classification Model remains in “In Progress” status for an extended period (more than 12 hours), this is typically caused by one of the following issues:Insufficient users in seed cohorts — The model encountered issues due to an absence of users in the cohorts when they were initially created. This commonly occurs when cohorts and models are generated on the same day, resulting in insufficient training data.Low unique users — The seed dataset does not have enough unique users to train a reliable model. Each Custom Cohort used as a label must have at least 1,000 users.Solution:
- Wait 24-48 hours after creating your seed cohorts to ensure they have accumulated sufficient users before creating a Classification Model
- Verify that each cohort in your seed dataset has at least 1,000 users
- If the issue persists after 12 hours, contact Support for assistance
Classification Cohort has low reach or accuracy
Classification Cohort has low reach or accuracy
If your deployed Classification Cohort shows lower than expected reach or accuracy, this may be due to the confidence threshold setting.Confidence threshold too high — Setting a very high confidence threshold (e.g., 90%+) will increase accuracy but significantly reduce reach, as fewer users will meet the minimum confidence requirement.Confidence threshold too low — Setting a very low confidence threshold (e.g., below 50%) will increase reach but may reduce accuracy, as the model will classify more users with lower certainty.Solution:
- Review the confidence threshold for your Classification Cohort
- Adjust the threshold to balance reach and accuracy for your use case
- Create multiple cohorts from the same model at different confidence thresholds to test performance
- Remember: At 0% confidence, the model assigns labels to 100% of users but predictions are essentially random; at 100% confidence, only users in the seed dataset are classified
Classification Cohort not activating to destination
Classification Cohort not activating to destination
If your Classification Cohort is not appearing in your ad server or activation destination, verify the following:Activation not enabled — The cohort may not be enabled for activation to your desired destination.SDK rebuild required — After creating a Classification Cohort, the Permutive SDK may need to be rebuilt to include the classification models addon.Unsupported platform — Classification Cohorts are only supported on Web, iOS, and Android platforms. They are not currently available for CTV or API Direct.Solution:
- Verify the cohort is enabled for activation in the dashboard
- Check that the activation destination (Google Ad Manager or Xandr) is properly configured
- Allow time for the SDK to rebuild and deploy (this can take several minutes)
- Confirm the platform where you’re attempting activation is supported
Environment Compatibility
Core Product
Classification Cohorts functionality is supported on the following platforms:| Functionality | Web | iOS | Android | CTV | API Direct |
|---|---|---|---|---|---|
| Activation | |||||
| Live audience size |
Insights
| Functionality | Web | iOS | Android | CTV | API Direct |
|---|---|---|---|---|---|
| Audience Insights | |||||
| Campaign Insights |
Activation
Classification Cohorts can be activated against the following destinations:Dependencies
Classification Cohorts rely on the following products being configured for your organization and workspace.| Dependency | Required | Description |
|---|---|---|
| Identity Graph | ~ | When using partner data, there must be a common identity configured in Identity Graph between you and the partner. |
| Custom Cohorts | ✓ | Custom Cohorts (excluding those using third-party data) are used for training and predicting Classification Cohorts. |
Limits
Classification Cohorts adhere to the following product SLAs.Feature Limits
| Feature | Description | Limit |
|---|---|---|
| Number of labels for first-party seed data | The number of Custom Cohorts that can be used as labels for each model. | 2–5 |
Performance Limits
| Metric | Description | Limit |
|---|---|---|
| Time to train a Classification Model | Once created in the dashboard, Classification Models may take up to 12 hours to train before they are ready to be used. | Up to 12 hours |
| Minimum number of users per Custom Cohort | For first-party seed datasets, a Custom Cohort must have at least 1,000 users to be used as a model label. | 1,000 users |
Usage Limits
| SKU | Description | Limit |
|---|---|---|
| Classification Models | Maximum number of active models each workspace can run at any time. | 10 models per workspace |
| Classification Cohorts | Maximum number of active cohorts each workspace can run at any time. | 30 cohorts per workspace |
FAQ
How long does it take to train a Classification Model?
How long does it take to train a Classification Model?
Classification Models can take up to 12 hours to train after being created in the dashboard. The exact training time depends on the size of your seed dataset and the complexity of the model.Once training is complete, the model will be automatically deployed and available for creating Classification Cohorts. You will be notified when training completes.
What's the difference between partner data and first-party data for Classification Models?
What's the difference between partner data and first-party data for Classification Models?
Partner data comes from external data providers (such as Fluent or OnAudience) and consists of a fixed, system-wide set of labels. Partner data allows you to reach your non-endemic audience by identifying which of your users have similar behavior to those in the partner dataset. For example, an auto publisher might use partner data from a luxury brand to identify users who are luxury watch intenders.First-party data comes from your own sources, such as declared data collected during sign-up or survey responses. With first-party data, you select 2-5 of your own Custom Cohorts to use as labels for the model. This allows you to scale your high-fidelity understanding of a subset of your audience to identify and reach users across your entire audience.
Can I use third-party data in my Custom Cohorts for training?
Can I use third-party data in my Custom Cohorts for training?
No. Classification Models are trained using your Custom Cohorts, excluding those using third-party data. This is intentional, as the goal of Classification Models is to help you scale your own first-party data or leverage partner datasets, not to amplify third-party data.
How do I choose the right confidence threshold?
How do I choose the right confidence threshold?
The confidence threshold determines the trade-off between accuracy and reach:
- Higher thresholds (70-90%): More accurate predictions but lower reach. Use when precision is critical.
- Medium thresholds (50-70%): Balanced accuracy and reach. Good starting point for most use cases.
- Lower thresholds (30-50%): Greater reach but lower confidence in predictions. Use when maximizing audience size is important.
How many Classification Models and Cohorts can I create?
How many Classification Models and Cohorts can I create?
Each workspace is limited to:
- 10 active Classification Models at any time
- 30 active Classification Cohorts at any time
Why do I need at least 1,000 users per Custom Cohort?
Why do I need at least 1,000 users per Custom Cohort?
For first-party seed datasets, each Custom Cohort used as a model label must have at least 1,000 users to ensure the model has sufficient training data. Models trained on cohorts with fewer users may fail to train or produce unreliable predictions.If your cohorts don’t yet have 1,000 users, wait for your audience to grow before creating the Classification Model. You can check cohort sizes in the dashboard before starting model training.
Where can Classification Cohorts be activated?
Where can Classification Cohorts be activated?
Classification Cohorts can be activated to:
- Google Ad Manager (GAM)
- Xandr (AppNexus)
Can I edit a Classification Model after it's been trained?
Can I edit a Classification Model after it's been trained?
No. Once a Classification Model has been created and trained, it cannot be edited. If you need to make changes to the seed dataset or labels, you must create a new Classification Model.However, you can create multiple Classification Cohorts from the same trained model by adjusting the confidence threshold and selecting different labels, without needing to retrain the model.
Changelog
For detailed changelog information, visit our
Changelog.